
So you have been playing Borderlands 4, and you’ve heard some of the usual hysterical dialogue that makes you lauch, and you think, “Hey, I’d like to make that into a ringtone!” Well, so did I, so I figured out now to extract the sounds and make an index of them.
To do the entire process, you’ll need both a Windows machine, and a Mac as there are parts that work on each, but not (easily) the other.
The first step is to extract the files. The “FModel.exe” tool on Windows is the tool to bulk extract the raw sound files from the game files. The settings that worked for me are as follows (obviously, adjust to match your hierarchy):
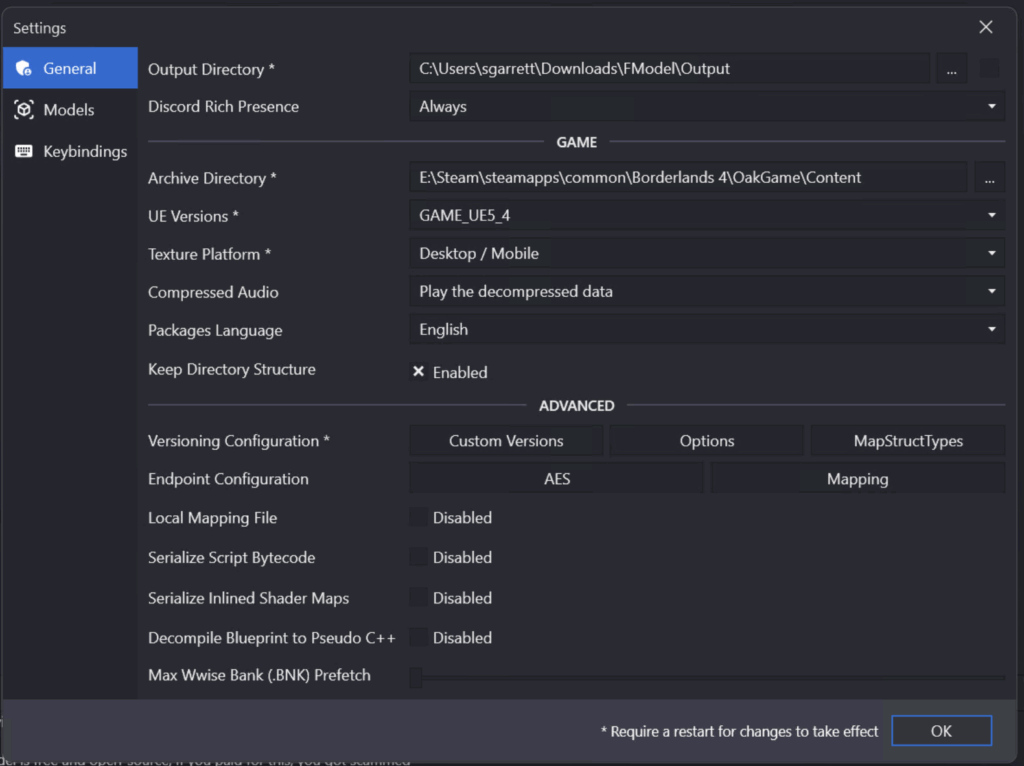
When you open the “\Steam\steamapps\common\Borderlands 4\OakGame\Content” folder of your game installation, you will get a list of “pakchunk” files of various kinds. For the game audio, the two key files (for English), are named “pakchunk2-Windows_0_P” and “pakchunk3-Windows_0_P”. #2 contains mostly sound effects and ambient sounds, with very little actual dialogue. #3 has all the dialogue. These are named so that it is easy for a computer to reference them, but for humans… not so much.
The Mercenary Day audio files are in pakchunk3-Windows_5_P.
So despite them all just being numbered .wem files, we are going to extract them all. The key here is to select the parent folder name, not to select all the files. If you try to extract them as separate files, FModel will collapse, cough up blood, and die. However, if you select the folder, and right click that, you can Export Folder's Raw Data, and it will dump all the files in bulk very quickly.
Now you have a folder with 70,000+ .wem files. So what do you do with those? They are, in fact, the audio files in “WWise” format, which is popular in video games, but not much outside of that environment. The tool I used is called ww2ogg. On the Mac, it can be installed with home brew or you can compile it yourself from the source.
You can mount the folder you extracted the files to on your Mac to work from. This is a little script that will convert the .wem files to ALAC .m4a files. You can, of course, direct ffmpeg to output to whatever you like:
#!/bin/bash -x
# Get just the name, without the path or the extension
NAME="${1%.*}"
NAME="${NAME##*/}"
# Copy the specified file to the current directory
cp "$1" .
# Convert the file to OGG, using the pcb file to hint the structure of the file
ww2ogg "${1##*/}" -o "${NAME}.ogg" --pcb "packed_codebooks_aoTuV_603.bin"
# Convert the OGG file to ALAC (or whatever you choose)
ffmpeg -y -loglevel quiet -stats -hide_banner -i "${NAME}.ogg" -c:a alac_at "${NAME}.m4a"
# Transcribe the speech into text for seraching
yap transcribe --txt "${NAME}.m4a" -o "${NAME}.txt"
# Get rid of the intermediary files.
rm "${NAME}.ogg" "${1##*/}"
I also use the yap tool on the Mac to do a speech-to-text conversion that is pretty accurate. Make sure the language is downloaded in Settings–>General–>Language & Regions–>Translation Languages or you will get an error.
The above script is to convert/translate a single file. If you want to process all the files, you would save that script as “ww2alac” or whatever you like, and make it executable (chmod 755 ww2alac). Then, you can iterate through a loop to process all of the files:
for file in /path/to/wemfiles/*.wem
{
ww2alac "$file"
}After running this, you will now have a folder with 70,000+ .m4a files and .txt files. I combined the .txt files into an index file which you can then use to search for the quotes you want and get the numeric ID of the file. I have attached the tab delimited text file here.
Yazınız için teşekkürler. Bu bilgiler ışığında nice insanlar bilgilenmiş olacaktır.
(Thank you for your article. In the light of this information, many people will be informed.)